Limiting Impact on the Production ODS
- Stephen Fuqua
- Ian Christopher (Deactivated)
This article describes patterns to help minimize potential performance impacts on the production ODS database.
Avoid Direct Query Mode
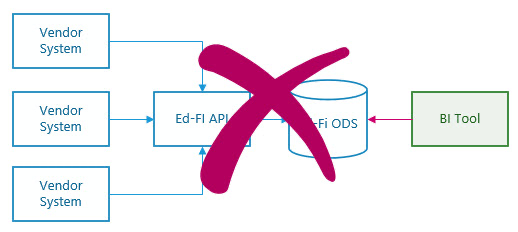
The production ODS database is (in theory) constantly receiving new data through calls to the API. The relational database is highly tuned for efficient storage and retrieval of individuals records; this makes queries not only difficult to write (hence the creation of this Analytics Middle Tier), but also leads to long wait times while complex queries execute.
Furthermore, a business intelligence system or report should probably read only committed data. If the transaction isolation level is set to REPEATABLE READ, READ COMMITTED, or SERIALIZABLE, then long-running queries run the risk of locking tables and preventing the API from updating them.
The following strategies, taken individually or in combination, can reduce the risk of negative impact to the production instance of the ODS.
Read-Only Copy
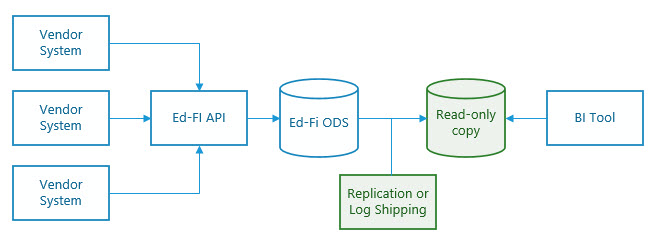
One common strategy for this sort of problem is to create a read-only copy of the production system, and run all complex queries from this copy instead of from the writable system. Three techniques are available with SQL Server:
Replication works through subscriptions and schedules and can duplicate partial databases instead of the entire database. The log shipping technique actually starts with a backup-and-restore and then copies and replays transaction logs to a secondary server. The third technique makes use of Always On availability groups, using one of the secondary servers as a realtime read-only copy.
If external systems are updating the ODS through the API on a constant basis, then it may make sense to refresh the secondary several times per day. If real-time support is desired, then replication is the optimal solution. If the system can tolerate periodic refresh of data, then log shipping might be the preferred approach, as it is generally simpler to use than the equivalent snapshot replication. However, if disk storage or security are concerns, snapshot replication can be effective for scheduling duplication of only the tables needed by the Analytics Middle Tier queries.
There are also some third-party replication solutions that could be useful as alternatives to the Microsoft-based approaches.
Materialized Views
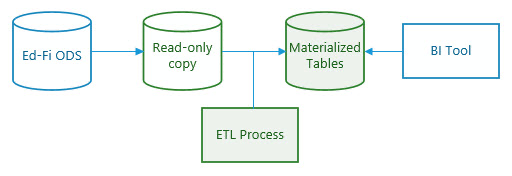
While creating a read-only copy helps to avoid causing problems on the production system, it does little or nothing to improve the query performance. The materialized views technique queries the source tables (ideally in a read-only copy of the ODS) and loads the output into new tables. These new tables can have their own indexing strategy, and queries off of them will perform significantly better than queries against the views.
Some of the drawbacks of this approach include the need to schedule a refresh or replacement of the new tables, additional process monitoring, and the added storage cost associated with these large denormalized tables.
The Early Warning System sample scripts include a "datamart" solution that creates materialized tables with indexes that support all of the relationships in the model. It creates these tables in a tertiary database. Although a large number of ODS source tables are not used, when created from the Glendale data set, the tertiary database is of similar size to the original database.
Although three database instances might now be in play, the read-only secondary and materialized-view tertiary instances could easily be on the same server instance.
Analytics Engine Caching
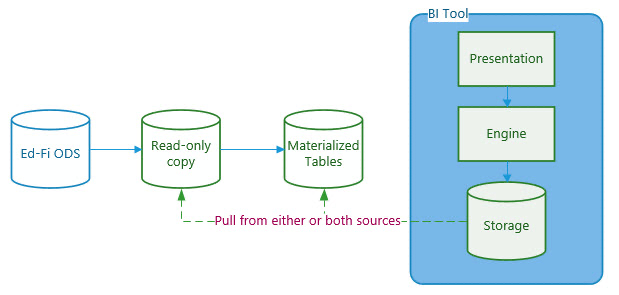
Many business intelligence systems have a built-in analytics engine that includes a database optimized for high-performance queries (e.g., Microsoft's Tabular Data). These tools can often query a source system on a schedule and store the results in their own caching mechanism or database. When such a system is available, it will likely be a better choice than using materialized views. However, it may still be advantageous to load the analytics engine from a read-only view.
If the analytics engine is not advanced enough to support all of the desired calculations, then it may be useful to perform calculations off of materialized view tables before importing data into the analytics engine.
Contents