Introduction
Analytics Middle Tier 2.0 is becoming a full citizen in the Ed-Fi platform in 2020, rather than just a proof-of-concept on the Ed-Fi Exchange. As it grows up, it needs to correct some architectural concerns that came up as feedback from the field. It also needs to be up to par with the latest release of the ODS/API, version 3.3. This document aims to inform about the challenges and elicit feedback on the real-world usefulness of the proposed solutions.
Naming Convention
Requirement
Hold names to under 63 characters for PostgreSQL compatibility.
Design
Currently, none of the objects have a name that violates this constraint. To help avoid problems with future views, it is proposed to either truncate "Dimension" to "Dim" or drop the word altogether. Generally, clarity should be preferred over length when naming objects, hence the question is: how much clarity is lost if we move away from the "Dimension" suffix?
| Old Name | A - Truncate | B - Drop |
|---|---|---|
| analytics.StudentDimension | analytics.StudentDim | analytics.Student |
| Info |
|---|
Is there too much risk of confusing the |
| Tip | ||
|---|---|---|
|
| Warning |
|---|
This is a substantial breaking change compared to 1.0. Since 1.0 adoption is limited, this breaking change would also be very limited - but it needs to happen now if it is going to happen. Requesting additional input before committing. Respond to Stephen Fuqua, #dev-analytics-middle-tier on Slack, or with a comment on this page. |
Multi Data Standard Support
Requirement
Support installing the views onCommitting to "Dim" suffix on dimensions for best balance between name length and clarity of intent. Stephen Fuqua
|
Multi Data Standard Support
Requirement
Support installing the views on ODS databases supporting multiple data standards (2.2, 3.1, 3.2).
| Warning |
|---|
Is support for Data Standard 2 really necessary in this next release? Ed-Fi Alliance is committed to both 3.1 and 3.2 in all releases in 2020, but has not decided about 2.x. Welcoming input on this. |
Design
Version 1.3.0 added support for Data Standard 3.1, which wasDesign
Version 1.3.0 added support for Data Standard 3.1, which was used by ODS/API 3.1.1 and 3.2, through the use of the –dataStandard <Ds2 | Ds31> argument.
Forcing the user to remember which data standard is installed is sub-optimal. We should be able to detect this implicitly and install the correct version without user input.
- If table
AddressTypeexists, then install Data Standard 2. if needed
if needed - Else if table
VersionLevelexists, then install Data Standard 3.1. - Else if table
DeployJournalexists, then install Data Standard 3.2. - Else throw an error: "Unable to determine the ODS database version".
| Tip | ||
|---|---|---|
| ||
| Tip | ||
Will proceed with this design. Stephen Fuqua |
Student, Parent, and Staff Keys
Requirement
The views should expose "Key" fields based on the natural key of the underlying table.
Design
In the case of StudentDimension , ContactPersonDimension , and UserDimension , the original release used StudentUSI , ParentUSI , and StaffUSI respectively. The "USI" columns are primary keys and were used by mistake. The "UniqueId" columns are the correct natural keys.
Change all instances of StudentKey , ContactPersonKey , and UserKey to use the corresponding "UniqueId" column from the source table.
| Tip |
|---|
Will proceed with this design. Stephen Fuqua |
Descriptor and Type Mapping
Requirement
Decouple the views from hard-coded Descriptor and Type values.
Context
many of the views need to lookup records by Descriptor value - for instance, looking up the Attendance records where a student has an "Excused Absence" or "Unexcused Absence." Because the original developer had access to only a limited dataset, it was not realized that the Descriptor values will vary widely from one implementation to the next. Thus the hard-coding needs to be decoupled, allowing the implementation to provide a mapping from their Descriptor value to the concept used by the Analytics Middle Tier.
In theory, the various "Types" values in Data Standard 2 should provide a more universal constant than the Descriptors. However, some community members report that these too are mutable. Therefore, (a) using Types is not a solution for Data Standard 2, and (b) even those views with hard-coding to Types instead of Descriptors must be modified for greater independence. Note: Type tables were removed in Data Standard 3 precisely because they were not being used in the originally-designed manner.
Design
Summary
Data Standard 2 support plan:
|
Student, Parent, and Staff Keys
Requirement
The views should expose "Key" fields based on the natural key of the underlying table.
Design
In the case of StudentDimension , ContactPersonDimension , and UserDimension , the original release used StudentUSI , ParentUSI , and StaffUSI respectively. The "USI" columns are primary keys and were used by mistake. The "UniqueId" columns are the correct natural keys.
Change all instances of StudentKey , ContactPersonKey , and UserKey to use the corresponding "UniqueId" column from the source table.
| Tip | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
Will proceed with this design. Stephen Fuqua
|
Descriptor and Type Mapping
Requirement
Decouple the views from hard-coded Descriptor and Type values.
Context
many of the views need to lookup records by Descriptor value - for instance, looking up the Attendance records where a student has an "Excused Absence" or "Unexcused Absence." Because the original developer had access to only a limited dataset, it was not realized that the Descriptor values will vary widely from one implementation to the next. Thus the hard-coding needs to be decoupled, allowing the implementation to provide a mapping from their Descriptor value to the concept used by the Analytics Middle Tier.
In theory, the various "Types" values in Data Standard 2 should provide a more universal constant than the Descriptors. However, some community members report that these too are mutable. Therefore, (a) using Types is not a solution for Data Standard 2, and (b) even those views with hard-coding to Types instead of Descriptors must be modified for greater independence. Note: Type tables were removed in Data Standard 3 precisely because they were not being used in the originally-designed manner.
Design
Summary
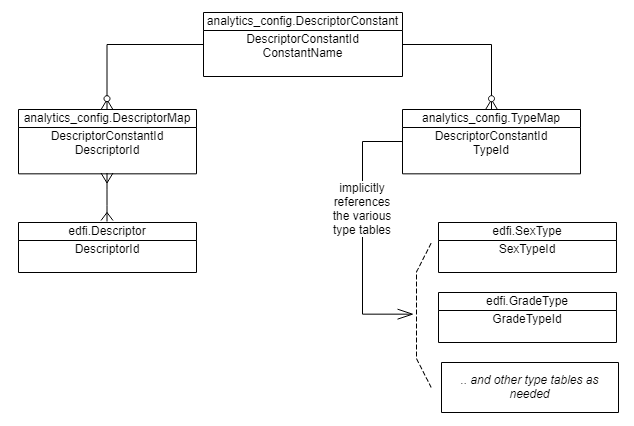
- Move hard-coded values to a "Constants" table.
- Create mapping tables that link Descriptors or Types to Constants.
- Modify all views as needed to join to the Constants and new mapping tables.
| Gliffy | ||||||
|---|---|---|---|---|---|---|
|
| Expand | ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||
|
Example
In Version 1.x, the StudentEarlyWarningFact view reports on excused and unexcused absences, looking for StudentSchoolAttendanceEvent records with attendance descriptor values of either "Excused Absence" or "Unexcused Absence".
In version 2, the view would now search for all StudentSchoolAttendanceEvent records whose descriptor maps to the relevant constant. Thus there would be two DescriptorMap values, one each for "Excused Absence" and "Unexcused Absence." Any school who uses a different term than these two would create a DescriptorMap record mapping that term to the DescriptorConstant value of "Absent".
Implications
Those who install the Analytics Middle Tier will need to carefully assess their Descriptors and Types, and then manage the DescriptorMap table (and TypeMap , for Data Standard 2) accordingly.
Default Mappings
A new command-line Option will be provided to run a script that loads the default Descriptor mapping for the default Ed-Fi descriptors (minimal/populated template descriptors).
| Code Block |
|---|
.\EdFi.AnalyticsMiddleTier.exe --connectionString "..." --options DefaultMap |
| Tip | ||
|---|---|---|
|
Will proceed with this design. Stephen Fuqua |
Student Dimension Uniqueness
|
Changes to the Student Dimension
Requirements
- Create a "Student" dimension with a single unique key.
- Provide intuitive access to student demographics.
Context
Student Dimension Uniqueness
The Early Warning System fact views both assumed that the StudentDimension would only have a single record for a student, as shown in these diagrams:
However, a student . However, a student could be enrolled in multiple schools at the same time, resulting in two records in the StudentDimension for the same StudentKey. This is problematic for the PowerBI Starter Kit, which has a hard requirement for unique StudentKeys.
At the same time, the Program-related fact and event views are looking at a Student in a given Local Education Agency, whereas the facts above are looking at a Student at a School. Although the ODS database supports a Student enrolled in a Program associated with a School, our input from the field tells us that Program association is on the LEA not the school. Thus we need to balance these competing tensions in any change to the data model.
Design
Data Standard 3 moved the student demographics into the StudentEducationOrganizationAssociation table, away from the Student table. The current StudentDimension view provides student name, primary contact, and demographics. The proposal is to split this into two different views, changing the Early Warning System star schema to a snowflake.
The demographics on the view are secondary to the student-school enrollment relationship. Therefore we will have a new view called StudentEnrollment to show active enrollment/school association information, with a StudentEnrollmentKey that combines the StudentUniqueId and SchoolId (maintaining the principal of needing only one column for a join). The early warning views would then change to use the single StudentEnrollmentKey in addition to the two separate StudentKey and SchoolKey columns. The original keys are retained to facilitate aggregating by student or school.
The StudentDimension would continue to exist in a reduced form, providing name and primary contact information. The Program views would continue to have the StudentKey in them (no changes).
Gliffy name StudentEnrollmentDimension pagePin 3
Impact on Security
By leaving StudentKey and SchoolKey in the views above, the current row-level security views will not require any changes.
Problem
What if someone wants to build queries that analyze program participation by demographic data?
Suppose we have the following data (partial representation):
ProgramTypeDimension
StudentProgramEvent
StudentEnrollmentDimension
Here a student is enrolled at two schools, presumably in the same district. Perhaps the program enrollment is due to a specialized class in the student's home language, at a different school than the one attended daily. Since data entry occurred twice - once for each school - there is an opportunity for inconsistency. In this case, one of the school enrollment entries failed to note that the student has limited English Proficiency.
We can write the following query to analyze this program proficiency by LimitedEnglishProficiency.
| Code Block |
|---|
select
ProgramTypeDimension.ProgramType,
count(1) as EnrolledCount,
sum(case when StudentEnrollmentDimension.LimitedEnglishProficiency <> 'Not applicable' then 1 else 0 end) as LimitedEnglishProficiencyCount
from
analytics.ProgramTypeDimension
inner join
analytics.StudentProgramEvent on ProgramTypeDimension.ProgramTypeKey = StudentProgramEvent.ProgramTypeKey
inner join
analytics.StudentEnrollmentDimension on StudentProgramEvent.StudentKey = StudentEnrollmentDimension.StudentKey
where
StudentProgramEvent.ProgramEventType = 'Enter'
group by
ProgramTypeDimension.ProgramType |
The result will be
In reality there is only one student, yet this naive query counted two students. And it will have the odd result of showing that 50% of the students have limited English proficiency!
Arguably, there is a data quality problem that the Analytics Middle Tier cannot solve. But there is also a training issue: the data analyst needs a deeper understanding of the nuances of Ed-Fi data storage and of the Analytics Middle Tier views. Ignoring the data inconsistency problem, the following query would resolve the double-count problem:
| Code Block |
|---|
select
ProgramTypeDimension.ProgramType,
count(1) as EnrolledCount,
sum(case when StudentDimensionEnrollment.LimitedEnglishProficiency <> 'Not applicable' then 1 else 0 end) as LimitedEnglishProficiencyCount
from
analytics.ProgramTypeDimension
inner join
analytics.StudentProgramEvent on ProgramTypeDimension.ProgramTypeKey = StudentProgramEvent.ProgramTypeKey
outer apply (
select distinct
LimitedEnglishProficiency
from
analytics.StudentEnrollmentDimension
where
StudentKey = StudentProgramEvent.StudentKey
) as StudentDimensionEnrollment
where
StudentProgramEvent.ProgramEventType = 'Enter'
group by
ProgramTypeDimension.ProgramType |
These problems are rather ugly, and would be difficult to detect unless you're actively looking for them. Furthermore, while writing an updated SQL query was easy, how would one represent this in a business intelligence tool like Tableau or PowerBI?
Status
| Warning |
|---|
Requesting additional input before committing. Respond to Stephen Fuqua, #dev-analytics-middle-tier on Slack, or with a comment on this page. |
School Year
Requirement
Add SchoolYear to help support longitudinal data.
Design
Data Standard 2's support for School Year is limited compared to Data Standard 3. The following dimension views could have a SchoolYear column in them:
The DateDimension view does not include a SchoolKey as it was intended as a generic date table. Although it strikes the writer as a nonsensical, there could be two different school years for the same date at different schools. Therefore it does not seem appropriate to add this column to the DateDimension.
There might be value in having the SchoolYear in the GradingPeriod and making the decision that Data Standard 2 would always return null for this column (so that the interfaces stay consistent): one could use this to create a filter hierarchy School Year > Grading Period. However, other than interpolating the begin and end dates on the Grading Period, there is currently no way to build out the hierarchy beyond this. The PeriodSequence is insufficient for determining a parent-child relationship between grading periods.
When trying to filter the StudentEarlyWarningFact or StudentSectionGradeFact views, the available school years could be extracted from either the Student or Student Section dimensions to create a slicer. However, this would be much simpler if the SchoolYear were simply included in those fact views.
Status
Requesting additional input before committing. Respond to Stephen Fuqua, #dev-analytics-middle-tier on Slack, or with a comment on this page.
Questions to address. Should we add a SchoolYear column to...
Separation Between Core and Use-Case Views
Requirement
Manage a collection of "core" views and separate collections of use-case specific views.
Design
The application already has a concept for installing optional components, which was first created for optional install of additional indexes in the ODS. Proposal:
Always install a core set of viewsMove some of the existing views into new optional collections:Row-level Security (RLS)
Early Warning System (EWS)
QuickSight-Early Warning System (Q-EWS)
Program Analysis (PROGRAM)
Establish clear standards for distinguishing view names and avoiding name overlapsOption 1: separate by "namespace" (schema). Instead of having a single
analytics schema, we could create an analytics_core schema and other schemas to match use cases:analytics_rlsfor Row-level Securityanalytics_ewsfor Early Warning Systemanalytics_quicksightfor QuickSightanalytics_programfor Program Analysis
Thus to install the Early Warning System and Row-level security collections used by the Power BI Starter Kit v2, the admin user would run this command:
| Code Block |
|---|
.\EdFi.AnalyticsMiddleTier.exe --connectionString "..." --options EWS RLS |
For deployment purposes, it would be ideal to separate these by "namespace" - or in SQL terms, by schema.
| Warning |
|---|
Requesting additional input before committing. Respond to Stephen Fuqua, #dev-analytics-middle-tier on Slack, or with a comment on this page. |
Additional Views
Will not add any new views in the 2.0 release. New views can be added with 2.1, 2.2 etc. This 2.0 release is all about fixing architectural problems and setting the stage for broader adoption.
| Note | ||
|---|---|---|
| ||
Work-in-progress draft. This notice will be removed when the "final" design decisions are documented. |
Demographics in Ed-Fi UDM v2.2
Sources for student demographics:
edfi.Studentcontains sex, Hispanic/Latino ethnicity, economic disadvantaged (Bool), school foodservice eligibility, limited English proficiency.- One-to-many tables:
edfi.StudentCohortYearedfi.StudentDisabilityedfi.StudentLanguageedfi.StudentLanguageUseedfi.StudentProgramAssociationedfi.StudentCharacteristicis a generic table, and contains begin/end dateedfi.StudentRace
Demographics in Ed-Fi UDM v3.x
Sources for student demographics:
edfi.StudentSchoolAssociationcontains School Year, Enrollment Date and Grade Leveledfi.StudentEducationOrganizationAssociationcontains Sex, Hispanic/Latino ethnicity, and Limited English Proficiency- There are a series of many-to-many tables to store specific types of multi-value demographic characteristics - note these can be saved for either the school or the district (or charter, state, ESC, etc.)
edfi.StudentEducationOrganizationAssociationCohortYearedfi.StudentEducationOrganizationAssociationDisabilityedfi.StudentEducationOrganizationAssociationLanguageedfi.StudentEducationOrganizationAssociationLanguageUseedfi.StudentEducationOrganizationAssociationRaceedfi.StudentEducationOrganizationAssociationTribalAffiliation
- And there is the generic
edfi.StudentEducationOrganizationAssociationStudentCharacteristictable, which has a time Period associated with it.- Includes food service eligibility, which was present on
Studentas a Boolean in version 1.
- Includes food service eligibility, which was present on
Dimension or Fact?
While gender, race, and ethnicity all have strings associated with them, some elements of the demographic and enrollment data are more fact-oriented than dimension-oriented:
- IsHispanic
- IsEconomicallyDisadvantaged
- LimitedEnglishProficiency
- SchoolEnrollmentDate
The ODS does not support slowly-changing dimensions, so there is only ever one current snapshot of these data - one cannot tie them to a date unless referring to the enrollment date... except in the case of food service eligibility because there is a time period.
Foodservice Eligibility
Foodservice eligibility is tracked via a Program Association, which not a demographic in the Ed-Fi Unified Data Model. Therefore it should be removed from demographics and placed in the program association views. For supporting the Power Bi Starter Kit, a new Early Warning System view might be needed that tries to preserve the old StudentDimension in some ways, including flattening the foodservice eligibility into a single Boolean value.
Design Proposal
Summary:
- Eliminate the idea of a separate "Student Dimension" in the core data collection.
- Create two new, very similar, dimensions to replace the old
StudentDimension:StudentSchoolDimStudentLocalEducationAgencyDim
- Combine the data from various
edfi.StudentEducationOrganizationAssociationXYZtables into a single view,DemographicDim. - Create two bridge tables to link student information to the characteristics
StudentSchoolDemographicBridgeStudentLocalEducationAgencyDemographicBridge
| Gliffy | ||||
|---|---|---|---|---|
|
Rationale for the Student Dimension replacement:
- Students don't (or shouldn't) exist in isolation from an organization - hence no need for a
StudentDim. - Across the Ed-Fi data model, there are two different student relationships:
- With the school (e.g. StudentSchoolAssociation, StudentDisciplineIncident, StudentGradebookEntry, etc.).
And with the more generic Education Organization - which in the current context of the Analytics Middle Tier, generally means Local Education Agency.
Note Exception: StudentAssessment is only connected directly to a Student! From analytics viewpoint, we will define the Analytics Middle Tier as assuming that analytics on assessment data will always be in the context of a School or Local Education Agency.
- In defining meaningful
StudentSchoolandStudentLocalEducationAgencyentities, there will be some overlap of fields - but the data could be different. This is an inherently dangerous area of the Ed-Fi data model. If we were to combine the data into a single perspective, then we would be hiding the danger. The data analyst will need to read and understand why there are two "root entities" for data reporting, and then choose which one to use based on their implementation. - The Analytics Middle Tier is intended for Local Education Agency use cases. Other use cases can be added in the future as needed to support other types of Education Organizations (e.g. a future view
StudentStateEducationAgencyDim).
Rationale for combining the various characteristic tables into a single point in time view:
- There are seven (in Data Standard 3+) similar characteristics tables that do not have time periods associated with them
- CohortYear
- Disability
- DisabilityDesignation
- Language
- LanguageUse
- Race
- TribalAffiliation
- And there is one with a time period: StudentCharacteristic
- Those without a time period can be combined into a single view for "demographics"
- Those without a time period can also be included in that view, so long as the data analyst understands that the "Bridge" between the student and the demographics represents "data as of right now".
- The two with a time period can, in the future, be used to create new Fact views that link to the date range. See Program Views below.
DemographicDim
Ultimately these values come from the edfi.Descriptor table, although not all descriptors will be here. String values will be used for keys instead of DescriptorId in order to allow combining data from multiple year-specific ODS databases into a single data mart - this would not be possible with the auto-incremented DescriptorId since that value will differ between ODS database instances.
Structure
| Column | Data Type | Source | Description |
|---|---|---|---|
| DemographicKey | String | "{Source Table}" or "{Source Table}.{Descriptor.CodeValue}" | Primary key. Made up of the table source and the Descriptor value. To support hierarchies, there will also be a root Key with only the table source value. |
| DemographicParentKey | String | same as above | Facilitates creation of roll-up / hierarchy in BI tools by relating each individual record to its "parent concept". |
| DemographicLabel | String | "{Descriptor}.{CodeValue}" for all Descriptors related to the relevant tables*. | For parent entities, will be the same as the Key. For child entities, will be the actual demographic label. |
Data Standard 2.2 Source Tables
Descriptors for the following tables:
- StudentCohortYear
- StudentDisability
- StudentLanguage
- StudentLanguageUse
- StudentRace
- StudentCharacteristic (where time dates encompass "now")
Student contains "IsEconomicDisadvantaged" in DS 2, whereas this is now one of the "StudentCharacteristics" in DS 3. In order to have parity between the two data standards, the DemographicDim view therefor needs a hard-coded row that does not come from a table:
| DemographicKey | ParentKey | DemographicLable |
|---|---|---|
| StudentCharacteristic#EconomicDisadvantaged | StudentCharacteristic | Economic Disadvantaged |
Otherwise the sample records will be as with the Data Standard 3+ samples below.
Data Standard 3+ Source Tables
Descriptors for the following tables:
- StudentEducationAgencyCohortYear
- StudentEducationAgencyDisability
- StudentEducationAgencyDisabilityDesignation
- StudentEducationAgencyLanguage
- StudentEducationAgencyLanguageUse
- StudentEducationAgencyRace
- StudentEducationAgencyTribalAffiliation
- StudentEducationAgencyStudentCharacteristic (where time StudentEducationAgencyStudentCharacteristicPeriod encompasses "now")
Sample Records
| DemographicKey | ParentKey | DemographicLabel |
|---|---|---|
| StudentCharacteristic | StudentCharacteristic | StudentCharacteristic |
| StudentCharacteristic#Economic Disadvantaged | StudentCharacteristic | Economic Disadvantaged |
| StudentCharacteristic#Homeless | StudentCharacteristic | Homeless |
| StudentCharacteristic#Runaway | StudentCharacteristic | Runaway |
| Race | Race | Race |
| Race#American Indian - Alaska Native | Race | American Indian - Alaska Native |
| Race#Asian | Race | Asian |
| Race#Black - African American | Race | Black - African American |
| Language | None | Language |
| Language#Adyghe | Language | Adyghe |
| Language#Swiss German | Language | Swiss German |
| etc. |
StudentSchoolDim
Data Standard 2.2
| Gliffy | ||||
|---|---|---|---|---|
|
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentSchoolKey | String | "{Student.StudentUniqueId}-{StudentSchoolAssociation.SchoolId}" | Primary key |
| StudentKey | String | edfi.Student.UniqueId | |
| SchoolKey | String | edfi.StudentSchoolAssociation.SchoolId | |
| SchoolYear | String | edfi.StudentSchoolAssocation.SchoolYear | convert to string to signal to modeling tools that this is not an aggregatable number |
| StudentFirstName | String | edfi.Student.FirstName | |
| StudentMiddleName | String | edfi.Student.MiddleName | |
| StudentLastName | String | edfi.Student.LastSurname | |
| EnrollmentDateKey | String | edfi.StudentSchoolAssociation.EntryDate | formatted as YYYY-MM-DD |
| GradeLevel | String | edfi.Descriptor.CodeValue via edfi.StudentSchoolAssociation.EntryGradeLevelDescriptorId | |
| LimitedEnglishProficiency | String | edfi.Descriptor.CodeValue via edfi.Student.LimitedEnglishProficiencyDescriptorId | Replace null with "Not Applicable" |
| IsHispanic | Boolean | edfi.Student.HispanicLatinoEthnicity | Replace null with 0 |
| Sex | String | edfi.SexType.CodeValue via edfi.Student.SexTypeId | |
| LastModifiedDate | DateTime | Most recent date from any source that has a LastModifiedDate column |
Data Standard 3+
| Gliffy | ||||
|---|---|---|---|---|
|
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentSchoolKey | String | "{Student.StudentUniqueId}-{StudentSchoolAssociation.SchoolId}" | Primary key |
| StudentKey | String | edfi.Student.UniqueId | |
| SchoolKey | String | edfi.StudentSchoolAssociation.SchoolId | |
| SchoolYear | String | edfi.StudentSchoolAssocation.SchoolYear | convert to string to signal to modeling tools that this is not an aggregatable number |
| StudentFirstName | String | edfi.Student.FirstName | |
| StudentMiddleName | String | edfi.Student.MiddleName | |
| StudentLastName | String | edfi.Student.LastSurname | |
| EnrollmentDateKey | String | edfi.StudentSchoolAssociation.EntryDate | formatted as YYYY-MM-DD |
| GradeLevel | String | edfi.Descriptor.CodeValue via edfi.StudentSchoolAssociation.EntryGradeLevelDescriptorId | |
| LimitedEnglishProficiency | String | edfi.Descriptor.CodeValue via edfi.StudentEducationOrganizationAssociation.LimitedEnglishProficiencyDescriptorId | Replace null with "Not Applicable" |
| IsHispanic | Boolean | edfi.StudentEducationOrganizationAssociation.HispanicLatinoEthnicity | Replace null with 0 |
| Sex | String | edfi.Descriptor.CodeValue via edfi.StudentEducationOrganizationAssociation.SexDescriptorId | |
| LastModifiedDate | DateTime | Most recent date from any source that has a LastModifiedDate column |
| Info |
|---|
The (first) primary contact was included in the original Student Dimension to further flatten the model. However, this had a large performance cost. To improve performance, flattening the primary contact is now left as an exercise for downstream semantic models - for example in a SSAS Tabular Data Model. |
StudentLocalEducationAgencyDim
Data Standard 2.2
| Gliffy | ||||
|---|---|---|---|---|
|
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentLocalEducationAgencyKey | String | "{Student.StudentUniqueId}-{School.LocalEducationAgencyId}" | Primary key |
| StudentKey | String | edfi.Student.UniqueId | |
| LocalEducationAgencyKey | String | edfi.School.LocalEducationAgencyId | |
| SchoolYear | String | edfi.StudentSchoolAssocation.SchoolYear | convert to string to signal to modeling tools that this is not an aggregatable number |
| StudentFirstName | String | edfi.Student.FirstName | |
| StudentMiddleName | String | edfi.Student.MiddleName | |
| StudentLastName | String | edfi.Student.LastSurname | |
| GradeLevel | String | edfi.Descriptor.CodeValue via edfi.StudentSchoolAssociation.EntryGradeLevelDescriptorId | |
| LimitedEnglishProficiency | String | edfi.Descriptor.CodeValue via edfi.Student.LimitedEnglishProficiencyDescriptorId | Replace null with "Not Applicable" |
| IsHispanic | Boolean | edfi.Student.HispanicLatinoEthnicity | Replace null with 0 |
| Sex | String | edfi.SexType.CodeValue via edfi.Student.SexTypeId | |
| LastModifiedDate | DateTime | Most recent date from any source that has a LastModifiedDate column |
Data Standard 3+
| Gliffy | ||||
|---|---|---|---|---|
|
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentLocalEducationAgencyKey | String | "{Student.StudentUniqueId}-{School.LocalEducationAgencyId}" | Primary key |
| StudentKey | String | edfi.Student.UniqueId | |
| LocalEducationAgencyKey | String | edfi.School.LocalEducationAgencyId | |
| SchoolYear | String | edfi.StudentSchoolAssocation.SchoolYear | convert to string to signal to modeling tools that this is not an aggregatable number |
| StudentFirstName | String | edfi.Student.FirstName | |
| StudentMiddleName | String | edfi.Student.MiddleName | |
| StudentLastName | String | edfi.Student.LastSurname | |
| GradeLevel | String | edfi.Descriptor.CodeValue via edfi.StudentSchoolAssociation.EntryGradeLevelDescriptorId | |
| LimitedEnglishProficiency | String | edfi.Descriptor.CodeValue via edfi.StudentEducationOrganizationAssociation.LimitedEnglishProficiencyDescriptorId | Replace null with "Not Applicable" |
| IsHispanic | Boolean | edfi.StudentEducationOrganizationAssociation.HispanicLatinoEthnicity | Replace null with 0 |
| Sex | String | edfi.Descriptor.CodeValue via edfi.StudentEducationOrganizationAssociation.SexDescriptorId | |
| LastModifiedDate | DateTime | Most recent date from any source that has a LastModifiedDate column |
StudentSchoolDemographicsBridge
Data Standard 2.2
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentSchoolDemographicBridgeKey | String | "{DemographicKey}-{StudentSchoolKey}" | Primary key |
| StudentSchoolKey | String | "{Student.StudentUniqueId}-{StudentSchoolAssociation.SchoolId}" | Foreign key |
| DemographicKey | String | DemographicDim.DemographicKey | Foreign key |
Must be composed of a series of union queries that combine records from these tables:
- StudentCohortYear
- StudentDisability
- StudentLanguage
- StudentLanguageUse
- StudentRace
- StudentCharacteristic (where time dates encompass "now")
As well as a record for "StudentCharacteristic#Economic Disadvantaged" if Student.IsEconomicDisadvantaged is true.
Data Standard 3+
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentSchoolDemographicBridgeKey | String | "{DemographicKey}-{StudentSchoolKey}" | Primary key |
| StudentSchoolKey | String | "{Student.StudentUniqueId}-{StudentSchoolAssociation.SchoolId}" | Foreign key |
| DemographicKey | String | DemographicDim.DemographicKey | Foreign key |
Must be composed of a series of union queries that combine records from these tables:
- StudentEducationOrganizationCohortYear
- StudentEducationOrganizationDisability
- StudentEducationOrganizationDisabilityDesignation
- StudentEducationOrganizationLanguage
- StudentEducationOrganizationLanguageUse
- StudentEducationOrganizationRace
- StudentEducationOrganizationTribalAffiliation
- StudentEducationOrganizationStudentCharacteristic (where StudentEducationOrganizationStudentCharacteristicPeriod dates encompass "now")
The joins need to be from Student → StudentSchoolAssociation → these tables, with StudentSchoolAssociation.SchoolId serving as the EducationOrganizationId in the joins.
StudentLocalEducationAgencyDemographicsBridge
Data Standard 2.2
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentLocalAgencyDemographicBridgeKey | String | "{DemographicKey}-{StudentLocalEducationAgencyKey}" | Primary key |
| StudentLocalEducationAgencyKey | String | "{Student.StudentUniqueId}-{School.LocalEduationAgencyId}" | Foreign key |
| DemographicKey | String | DemographicDim.DemographicKey | Foreign key |
Must be composed of a series of union queries that combine records from these tables:
- StudentCohortYear
- StudentDisability
- StudentLanguage
- StudentLanguageUse
- StudentRace
- StudentCharacteristic (where time dates encompass "now")
As well as a record for "StudentCharacteristic#Economic Disadvantaged" if Student.IsEconomicDisadvantaged is true.
Data Standard 3+
| Column | Data Type | Source | Description |
|---|---|---|---|
| StudentLocalAgencyDemographicBridgeKey | String | "{DemographicKey}-{StudentLocalEducationAgencyKey}" | Primary key |
| StudentLocalEducationAgencyKey | String | "{Student.StudentUniqueId}-{LocalEduationAgency.EducationOrganizationId}" | Foreign key |
| DemographicKey | String | DemographicDim.DemographicKey | Foreign key |
Must be composed of a series of union queries that combine records from these tables:
- StudentEducationOrganizationCohortYear
- StudentEducationOrganizationDisability
- StudentEducationOrganizationDisabilityDesignation
- StudentEducationOrganizationLanguage
- StudentEducationOrganizationLanguageUse
- StudentEducationOrganizationRace
- StudentEducationOrganizationTribalAffiliation
- StudentEducationOrganizationStudentCharacteristic (where StudentEducationOrganizationStudentCharacteristicPeriod dates encompass "now")
The joins need be from Student → StudentSchoolAssociation → School, with the School.LocalEducationAgencyId serving as the EducationOrganizationId in the other joins.
Alternatives
The following alternatives were considered and rejected
Split StudentDim into StudentDim and StudentEnrollmentDim
The original StudentDimension would be split in two: StudentDim with no SchoolKey in it and a StudentEnrollmentDim (or StudentDemographicDim ) holding the Student-to-school relationship and demographics. Rejected for these reasons:
- Trying to keep the number of views as small as possible, so that the domain model is easier to understand compared to the source Ed-Fi data model.
- Generally need to query for that student-school relationship - not for a student in isolation.
- Keeping only a single "enrollment" or "demographic" dimension for the student requires implementing business logic to determine which demographics take precedence - if demographics are saved for both school and local education agency, then when one should be used? Whichever choice is made, it will likely be wrong for many implementations.
Change StudentDim to StudentSchoolDim
In this version, the old StudentDimension is essentially renamed to StudentSchoolDim - largely preserving the old structure. Compared to the proposed model, this version allows the data analyst to quickly and easily find the right student information. It also relieves the analyst from having to decide which version of truth to use - the School or the Local Education Agency. As mentioned above, it has been decided that the Analytics Middle Tier should not gloss over this difficulty: the data analyst must inspect their implementation and decide which perspective (School or Local Education Agency) is appropriate in each circumstance.
Create Separate Bridge Tables for Each Demographic
Instead of combining the demographics into a single bridge view, we could have created one for each concept: Disability, Race, Tribal Affiliation, etc. On one level, this would have simplified the data analyst's work when looking for a particular demographic field: they can just look for the view with the word "Race" in the name, for example. However, this comes at the expense of proliferating more tables, making the Analytics Middle Tier look too much like the Ed-Fi data standard.
| Gliffy | ||||
|---|---|---|---|---|
|
| Tip | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
Planning to adopt this dual-root (Student-School and Student-LocalEducationAgency) approach. Stephen Fuqua
|
Program Views
Requirement
Support analytics on Program Participation at the school level.
Context
A small set of Program-related views was added to Analytics Middle Tier as an experiment in supporting a second use-case: analyzing student program participation. Programs in the default Ed-Fi ODS template include "Bilingual", "Career and Technical Education", "Special Education", and a few others. These data are represented in two different fact views: analytics.StudentProgramEvent and analytics.StudentProgramFact

The "Event" view represents the date on which a student entered or exited a program. The "Fact" view represents every day on which the student was in a program. Each perspective has its own utility in analytics / reporting.
Note, however, that they both join to analytics.LocalEducationAgencyDimension . There is no linkage to schools. This is because the data modeler originally heard (or thought he heard) that program enrollment is "always" at the district level. Since then, he has received feedback that many implementations do link students to programs at the school level, or even at the state level.
Design
a Remove the Views
Eliminate the problem by eliminating the views, unless and until we get a detailed real-world use case definition that would solve these problems.
b Add a SchoolKey to Both Views
This implies that SchoolKey or LocalEducationAgencyKey could be null, generally an undesirable situation in dimensional modeling. A few options:
- Ignore the problem: downstream data analyst have to join the program views to
SchoolDimensionorLocalEducationAgencyDimensionwith an outer join. Good for data architect.
Good for data architect.- Dangerous for data analyst.
- Nulls can be eliminated - or at least nearly eliminated - for
LocalEducationAgencyKeyby loading a School'sLocalEducationAgencyKeyvalue.- Moderate additional complexity for data architecture.
- Resolves one outer join problem but leaves the other in place.
- Create a "fake school" for each LEA in the
SchoolDimension, withSchoolName = 'n/a'. Use this as theSchoolKeywhen program participation is only at the LEA level.- Ugly for the data architect, although not impossible.
- Resolves the other outer join problem, at the expense of having a strange "District" entry show up in School filters. Dubious value.
- Separate the views into copies for School and LocalEducationAgency.
 Just forces the problem onto the data analyst.
Just forces the problem onto the data analyst.
The Data Standard shows that a School can belong to 0 or 1 Local Education Agency. Side note: that Agency might be a Charter Management Organization. Thus option 2 can still lead to lost records when using an INNER JOIN. As with Option 3, null/missing records can be eliminated by creating a "n/a" LocalEducationAgency for these schools.
If these program views are to be kept, then a combination of options 2 and 3 seems like the only option that presents a useful interface to the data analyst.
| Tip | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Going to defer for a real use case so that we don't mislead anyone. Taking the program views out of Analytics Middle Tier 2.0. Must remember to address FoodService when coming back to this in Analytics Middle Tier 2.1+.
|
School Year
Requirement
Add SchoolYear to help support longitudinal data / multi-year databases. Wherever possible, would be nice to support drill-down hierarchies by school year.
Design
The following dimension views could have a SchoolYear column in them; Data Standard 2's support for School Year is limited compared to Data Standard 3.
| Data Standard 2 | Data Standard 3 |
|---|---|
| Student / Student Enrollment | Student / Student Enrollment |
| Student Section | Student Section |
| Date | |
| Grading Period |
The multi-year use-case was not originally one of the goals of the Analytics MIddle Tier, so no consideration was given to adding to the two views that could support it. It will be trivial to add to these two views in common above.
For Date and Grading Period, there is real value. To support in Data Standard 2, we would need to create a mapping table or extra column on each of those two tables. This takes into account that one record could below to multiple school years in some edge cases. The additional effort required may push solving for Date and Grading Period to a future release, e.g. Analytics Middle Tier 2.1.
| Tip | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Decided to support SchoolYear in the student-school relationship and in the student-section relationship in Analytics Middle Tier 2.0. SchoolYear column will exist for Data Standard 2 but will not be populated where not available. Stephen Fuqua
|
Separation Between Core and Use-Case Views
Requirement
Manage a collection of "core" views and separate collections of use-case specific views.
Design
The application already has a concept for installing optional components, which was first created for optional install of additional indexes in the ODS. Proposal:
- Always install a core set of views
- ContactPersonDimension
- DateDimension
- GradingPeriodDimension
- LocalEducationAgencyDimension
- MostRecentGradingPeriod
- SchoolDimension
- SchoolNetworkAssociationDimension
- StudentDimension
- StudentEnrollmentDimension (if created, see above)
- StudentSectionDimension
- Move some of the existing views into new optional collections:
- Row-level Security (RLS)
- StudentDataAuthorization
- UserAuthorization
- UserDimension
- Early Warning System (EWS)
- StudentEarlyWarningFact
- StudentSectionGradeFact
- QuickSight-Early Warning System (QEWS)
- Ews_SchoolRiskTrend
- Ews_StudentAttendanceTrend
- Ews_StudentEnrolledSectionGrade
- Ews_StudentEnrolledSectionGradeTrend
- Ews_StudentIndicators
- Ews_StudentIndicatorsByGradingPeriod
- Ews_UserSchoolAuthorization
- Program Analysis (PROGRAM)
- ProgramTypeDimension
- StudentProgramEvent
StudentProgramFact
Tip Thus to install the Early Warning System and Row-level security collections used by the Power BI Starter Kit v2, the admin user would run this command:
Code Block .\EdFi.AnalyticsMiddleTier.exe --connectionString "..." --options EWS RLS
- Row-level Security (RLS)
- Avoid name overlaps
Option 1: separate by "namespace" (schema). Instead of having a single
analyticsschema, we could create ananalytics_coreschema and other schemas to match use cases:v1 Name v2 Name analytics.ContactPersonDimension analytics_core.ContactPersonDimension analytics.DateDimension analytics_core.DateDimension analytics.Ews_SchoolRiskTrend analytics_qews.SchoolRiskTrend analytics.Ews_StudentAttendanceTrend analytics_qews.StudentAttendanceTrend analytics.Ews_StudentEnrolledSectionGrade analytics_qews.StudentEnrolledSectionGrade analytics.Ews_StudentEnrolledSectionGradeTrend analytics_qews.StudentEnrolledSectionGradeTrend analytics.Ews_StudentIndicators analytics_qews.StudentIndicators analytics.Ews_StudentIndicatorsByGradingPeriod analytics_qews.StudentIndicatorsByGradingPeriod analytics.Ews_UserSchoolAuthorization analytics_qews.UserSchoolAuthorization analytics.GradingPeriodDimension analytics_core.GradingPeriodDimension analytics.LocalEducationAgencyDimension analytics_core.LocalEducationAgencyDimension analytics.MostRecentGradingPeriod analytics_core.MostRecentGradingPeriod analytics.ProgramTypeDimension analytics_program.ProgramTypeDimension analytics.SchoolDimension analytics_core.SchoolDimension analytics.SchoolNetworkAssociationDimension analytics_core.SchoolNetworkAssociationDimension analytics.StudentDataAuthorization analytics_rls.StudentDataAuthorization analytics.StudentDimension analytics_core.StudentDimension analytics.StudentEarlyWarningFact analytics_ews.StudentEarlyWarningFact analytics.StudentProgramEvent analytics_program.StudentProgramEvent analytics.StudentProgramFact analytics_program.StudentProgramFact analytics.StudentSectionDimension analytics_core.StudentSectionDimension analytics.StudentSectionGradeFact analytics_ews.StudentSectionGradeFact analytics.UserAuthorization analytics_rls.UserAuthorization analytics.UserDimension analytics_rls.UserDimension analytics.UserStudentDataAuthorization analytics_rls.UserStudentDataAuthorization Option 2: keep everything in a single schema, ensuring unique names, so that downstream data models (without namespaces/schemas) do not need to name their models differently than the views. Put use case name as object name prefix.
v1 Name v2 Name analytics.ContactPersonDimension analytics.ContactPersonDim analytics.DateDimension analytics.DateDim analytics.Ews_SchoolRiskTrend analytics.qews_SchoolRiskTrend analytics.Ews_StudentAttendanceTrend analytics.qews_StudentAttendanceTrend analytics.Ews_StudentEnrolledSectionGrade analytics.qews_StudentEnrolledSectionGrade analytics.Ews_StudentEnrolledSectionGradeTrend analytics.qews_StudentEnrolledSectionGradeTrend analytics.Ews_StudentIndicators analytics.qews_StudentIndicators analytics.Ews_StudentIndicatorsByGradingPeriod analytics.qews_StudentIndicatorsByGradingPeriod analytics.Ews_UserSchoolAuthorization analytics.qews_UserSchoolAuthorization analytics.GradingPeriodDimension analytics.GradingPeriodDim analytics.LocalEducationAgencyDimension analytics.LocalEducationAgencyDim analytics.MostRecentGradingPeriod analytics.MostRecentGradingPeriod analytics.ProgramTypeDimensionanalytics.program_ProgramTypeDimensionanalytics.SchoolDimension analytics.SchoolDim analytics.SchoolNetworkAssociationDimension analytics.SchoolNetworkAssociationDim analytics.StudentDataAuthorization analytics.rls_StudentDataAuthorization analytics.StudentDimension analytics.StudentDim analytics.StudentEarlyWarningFact analytics.ews_StudentEarlyWarningFact analytics.StudentProgramEventanalytics.program_StudentProgramEventanalytics.StudentProgramFactanalytics.program_StudentProgramFactanalytics.StudentSectionDimension analytics.StudentSectionDim analytics.StudentSectionGradeFact analytics.ews_StudentSectionGradeFact analytics.UserAuthorization analytics.rls_UserAuthorization analytics.UserDimension analytics.rls_UserDim analytics.UserStudentDataAuthorization analytics.rls_UserStudentDataAuthorization Option 3: keep everything in single schema and don't force prefixing for use cases. Just have clear and unique names for views. Prefix on case-by-case basis.
Note Leaning toward option (b). Additional benefit: helps the reader know where to look up additional information about use-case specific views, such as important usage notes.
| Tip | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Going with option (b). Stephen Fuqua
|
Additional Views
Will not add any new views in the 2.0 release. New views can be added with 2.1, 2.2 etc. This 2.0 release is all about fixing architectural problems and setting the stage for broader adoption.
Documentation
End-Users
Decisions made in defining the Ed-Fi data model are allowing a great deal of flexibility in storing data, at the expense of un-intuitive complexity. Users of the Analytics Middle Tier need to know about the complexities in order to use this tool effectively. For example, if adopting option (b) to solve the Program view problem, there needs to be clear guidance to help the end-user.
Users also need to be made aware of potential data quality issues, for example with the Student Demographics. If a student is enrolled in two schools at a time, and they don't both enter the same demographic information (e.g. one accidentally clicks on the wrong gender, or one does not mark student as Hispanic/Latino), then how will the data analyst know and reconcile this? The Ed-Fi Alliance cannot prescribe an answer: it depends on the implementation.
For the (rare?) case that the console deployment tool does not work, provide guidance on directly accessing the views from the source code repository. Warn that scripts, when manually executed, need to be run in numeric order of file name, starting with the Core collection first and then installing other collections as needed.
Other issues will likely arise, so that end-user documentation will be an ongoing exercise.
Contributors
Documentation for contributors to the project will need to spell out how to contribute; how to create use-cases; naming conventions; when and how to place a new view into the Core collection.
Version 2 versus Version 3 support.
| Table of Contents | ||
|---|---|---|
|